De la física estadística a la IA
Hay algo profundamente elegante en descubrir que las ecuaciones que gobiernan el comportamiento de miles de millones de partículas en un gas son, esencialmente, las mismas que permiten que un modelo de lenguaje prediga la próxima palabra en una oración. No es una analogía vaga ni una metáfora inspiradora: es una identidad matemática precisa. Este artículo recorre el puente que une la física estadística del siglo XIX con la inteligencia artificial del siglo XXI, pasando por el álgebra lineal, la teoría de la probabilidad y la arquitectura de las redes neuronales modernas.
Table of contents
Open Table of contents
- 1. Intro ilustrada
- 2. Álgebra lineal: el esqueleto invisible
- 3. Probabilidad, entropía y el arte de aprender
- 4. La física entra en escena: Boltzmann, Gibbs y la función softmax
- 5. De Hopfield a los transformers: un linaje inesperado
- 6. Entrenamiento y fine-tuning: la física en acción
- 7. La temperatura de sampling: donde todo se encuentra
- 8. Conclusión: la unidad profunda de las matemáticas
- 9. Explorador interactivo
1. Intro ilustrada
Si no carga en esta vista, abrilo en una pestaña nueva.
2. Álgebra lineal: el esqueleto invisible
Todo comienza con matrices. Si alguna vez te preguntaste qué tienen en común una red neuronal profunda, un motor de recomendaciones y un modelo de lenguaje como GPT, la respuesta es simple: operaciones sobre tensores.
Cuando un transformer procesa una oración, cada palabra se convierte en un vector -un embedding- que vive en un espacio de cientos o miles de dimensiones. Esa representación vectorial no es arbitraria: palabras con significados similares ocupan regiones cercanas en ese espacio, una propiedad que emerge del entrenamiento y que tiene profundas raíces en el álgebra lineal.
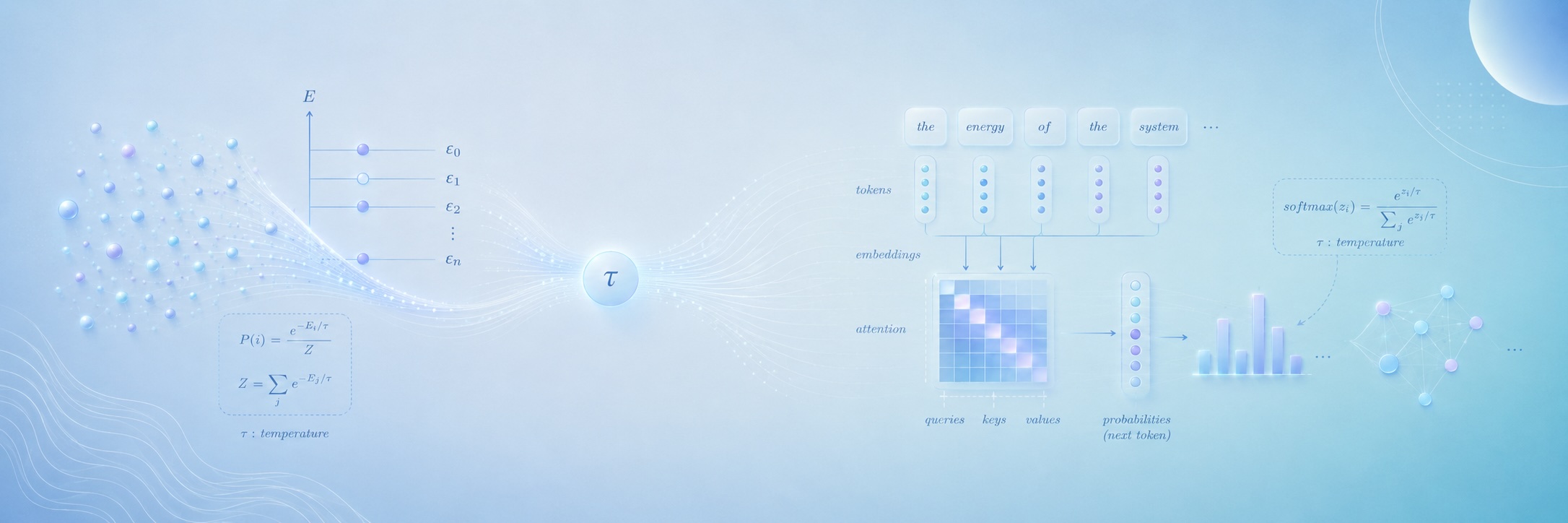
El mecanismo de atención, el corazón de los transformers, es pura álgebra lineal en acción. Dada una secuencia de tokens, se generan tres matrices: Queries (Q), Keys (K) y Values (V). El producto (donde indica la transpuesta de ) produce una matriz de similitud entre todos los pares de tokens. Esa matriz se escala, se normaliza con softmax -y acá aparece la primera conexión con la física- y se multiplica por V para producir la salida. Este mecanismo fue presentado en 2017 en el paper seminal “Attention Is All You Need” y cambió para siempre el campo de la IA.
Lo fascinante es que este proceso, que parece un simple truco de álgebra, permite que el modelo “preste atención” a relaciones arbitrariamente lejanas en el texto. La multiplicación de matrices, esa operación que aprendemos en el secundario, es el motor que mueve la inteligencia artificial moderna.
3. Probabilidad, entropía y el arte de aprender
Si el álgebra lineal es el esqueleto, la teoría de la probabilidad es el sistema nervioso. Una red neuronal no “sabe” cosas en el sentido humano: produce distribuciones de probabilidad sobre posibles resultados.
Cuando un LLM genera texto, lo que realmente hace es calcular, token por token, una distribución de probabilidad condicional: . Es decir, dado todo lo anterior, ¿cuál es la probabilidad de cada posible palabra siguiente?
El entrenamiento consiste en ajustar los parámetros de la red para que esta distribución se parezca lo más posible a la distribución real observada en los datos. La métrica que mide esa diferencia es la entropía cruzada, un concepto que Claude Shannon tomó prestado de la termodinámica en 1948 para fundar la teoría de la información.
Y acá aparece otra conexión maravillosa: minimizar la entropía cruzada es matemáticamente equivalente a maximizar la verosimilitud (“maximum likelihood estimation”), uno de los pilares de la estadística frecuentista. Dos tradiciones -la información y la estadística- convergen en la misma función de pérdida.
4. La física entra en escena: Boltzmann, Gibbs y la función softmax
Llegamos al corazón del asunto. La función softmax, que aparece en cada capa de atención de cada transformer, en cada clasificador de cada red neuronal, tiene esta forma:
Donde (tau) es un parámetro que en machine learning se llama “temperatura”. ¿Te suena familiar?
En 1877, Ludwig Boltzmann derivó la distribución que lleva su nombre para describir cómo se distribuyen las energías de las partículas en un sistema en equilibrio térmico:
Es la misma fórmula. La temperatura en física es la temperatura en machine learning. Las energías son los logits (con un signo negativo que se absorbe en la definición). La constante de Boltzmann es irrelevante porque se cancela en el cociente.
Esto no es una coincidencia: ambas fórmulas emergen del mismo principio variacional. Tanto en física como en machine learning, la distribución softmax/Boltzmann es la que maximiza la entropía sujeta a una restricción de energía media (o de logit medio). Es la distribución “más desordenada posible” compatible con lo que sabemos.
Cuando un LLM genera texto con temperatura baja (), la distribución se concentra en el token más probable: el modelo se vuelve determinista, “frío”. Cuando la temperatura es alta (), la distribución se aplana: el modelo se vuelve creativo, impredecible, “caliente”. Estás manipulando la misma perilla termodinámica que gobierna el comportamiento de un gas.
5. De Hopfield a los transformers: un linaje inesperado
La conexión entre física y redes neuronales no es nueva. En 1982, John Hopfield -un físico de formación- propuso un modelo de memoria asociativa inspirado directamente en el modelo de Ising, que describe el magnetismo en redes de espines.
Las redes de Hopfield almacenan patrones como mínimos de una función de energía. Recordar un patrón consiste en hacer un descenso por esa superficie de energía hasta caer en el mínimo correspondiente. Es una idea tomada directamente de la física del estado sólido.
Aunque las redes de Hopfield cayeron en desuso práctico, la intuición física que las animaba -tratar el aprendizaje como un problema de minimización de energía- se convirtió en el paradigma dominante. El descenso de gradiente estocástico (SGD), el algoritmo que entrena prácticamente todas las redes neuronales modernas, es una forma de minimizar una “energía libre” que la red define implícitamente sobre el espacio de parámetros.
En 2024, el Premio Nobel de Física fue otorgado a John Hopfield y Geoffrey Hinton “por descubrimientos fundamentales que permiten el aprendizaje automático con redes neuronales artificiales”. La física y la IA comparten, literalmente, un Nobel.
6. Entrenamiento y fine-tuning: la física en acción
Cuando se entrena un LLM como GPT o Llama desde cero, el proceso puede describirse íntegramente en el lenguaje de la física estadística. Esta conexión es tan profunda que existe una rama entera de la literatura académica dedicada a introducir machine learning a físicos usando justamente estas analogías:
- Espacio de fases: los miles de millones de parámetros de la red definen un espacio de configuración de dimensionalidad astronómica.
- Función de energía: la función de pérdida (cross-entropy) asigna una “energía” a cada configuración de parámetros. Configuraciones con baja pérdida = baja energía = estados más probables.
- Descenso de gradiente: el algoritmo sigue la dirección de máxima pendiente negativa en esta superficie de energía, como una partícula que rueda cuesta abajo.
- Stochastic Gradient Descent (SGD): la componente estocástica -los minibatches aleatorios- actúa como una temperatura efectiva que permite al sistema escapar de mínimos locales malos, de forma análoga al ruido térmico en sistemas físicos.
- Simulated annealing: una técnica de optimización tomada directamente de la metalurgia, donde se reduce gradualmente la “temperatura” del sistema para que se asiente en un mínimo profundo.
El fine-tuning -ajustar un modelo pre-entrenado para una tarea específica- también tiene su análogo físico: es como tomar un sistema que ya alcanzó un equilibrio (el pre-entrenamiento) y modificar levemente las condiciones de contorno para que se reacomode en un nuevo equilibrio cercano.
Incluso técnicas modernas como LoRA (Low-Rank Adaptation), que descompone las actualizaciones de pesos en matrices de bajo rango para hacer el fine-tuning más eficiente, son una aplicación directa de conceptos de álgebra lineal -descomposición en valores singulares, aproximación de bajo rango- que tienen análogos en la física de sistemas con muchas partículas donde solo unos pocos grados de libertad son relevantes.
7. La temperatura de sampling: donde todo se encuentra
Quizás el ejemplo más tangible de esta conexión es el parámetro de temperatura que se usa al generar texto con un LLM. Es un valor que va típicamente de 0 a 2:
- : el modelo siempre elige el token más probable. Respuestas deterministas, repetitivas, “congeladas”.
- : un equilibrio entre coherencia y creatividad. El valor por defecto en muchas interfaces con LLMs.
- : el modelo explora tokens menos probables. Respuestas sorprendentes, a veces incoherentes.
- : distribución uniforme. El modelo elige tokens al azar. Ruido puro.
Estás ajustando la temperatura de un gas de partículas que, en este caso, son tokens. Un gas caliente explora más configuraciones; un gas frío se queda en el estado fundamental. La intuición física es perfecta.
8. Conclusión: la unidad profunda de las matemáticas
Lo que hace especialmente hermoso este recorrido es que no se trata de analogías forzadas. La función softmax es la distribución de Boltzmann. La entropía cruzada es la energía libre de Helmholtz en un sistema de partículas no interactuantes. El descenso de gradiente es la relajación de un sistema físico hacia el equilibrio. La temperatura de sampling es la temperatura termodinámica.
Las mismas ecuaciones que Boltzmann escribió para explicar por qué un gas se expande son las que permiten que un modelo de lenguaje escriba poesía. Las mismas integrales que Gibbs usó para unificar la termodinámica con la mecánica estadística son las que aparecen en la inferencia variacional que acelera el entrenamiento de redes neuronales.
Esta unidad profunda no es un accidente: refleja el hecho de que tanto la naturaleza como la inteligencia artificial están resolviendo el mismo problema fundamental -cómo procesar información en sistemas con un número astronómico de grados de libertad- y, por lo tanto, arriban a las mismas soluciones matemáticas.
La próxima vez que uses ChatGPT, Claude o cualquier LLM, recordá que detrás de cada token generado hay más de un siglo de física, desde los átomos de Boltzmann hasta los Transformers de Google. La inteligencia artificial no es solo ingeniería: es física aplicada.
9. Explorador interactivo
Si no carga en esta vista, abrilo en una pestaña nueva.
Si te gustó este artículo, compartilo con alguien que disfrute tanto de la ciencia como de entender cómo funcionan realmente las cosas.
Referencias (con links verificados):
-
Boltzmann, L. (1877). Über die Beziehung zwischen dem zweiten Hauptsatze der mechanischen Wärmetheorie und der Wahrscheinlichkeitsrechnung. Sitzungsberichte der mathematisch-naturwissenschaftlichen Classe der Kaiserlichen Akademie der Wissenschaften, 76, 373-435.
- Paper fundacional de la mecánica estadística. Referencia académica completa; el original está disponible en colecciones históricas.
-
Shannon, C. E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal, 27(3), 379-423.
-
Hopfield, J. J. (1982). Neural networks and physical systems with emergent collective computational abilities. Proceedings of the National Academy of Sciences, 79(8), 2554-2558.
-
Hinton, G. E., & Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. Science, 313(5786), 504–507.
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems (NeurIPS), 30.
-
Mehta, P., Bukov, M., Wang, C. H., Day, A. G. R., Richardson, C., Fisher, C. K., & Schwab, D. J. (2019). A high-bias, low-variance introduction to Machine Learning for physicists. Physics Reports, 810, 1-124.
-
The Nobel Prize in Physics 2024. NobelPrize.org. Nobel Prize Outreach AB.
Recursos complementarios:
- How deep is the connection between the softmax function in ML and the Boltzmann distribution? - Cross Validated (StackExchange). https://stats.stackexchange.com/questions/347666/
- Cross-entropy - Wikipedia. https://en.wikipedia.org/wiki/Cross-entropy
- Efficient attention explained: the math behind linear-time transformers - LambdaClass Blog. https://blog.lambdaclass.com/efficient-attention-explained/